High Performance Computing (HPC) networking is very different to the traditional networks that ISP’s, businesses and enterprises build. The ideas and concepts are orthogonal.
The whole system has to be thought of as a single ‘computer’ with an internal fabric joining it together. HPC fabrics are mostly ‘set and forget’: initially requiring substantial setup and configuration, but with few changes over the life of the system.
The critical concept of HPC fabrics is to have massive scalable bandwidth (throughput) whilst keeping the latency ultra-low. In this four-part series we discuss what makes HPC Networking truly unique. This is part 1: Latency. Look out for parts 2-4 in the coming weeks.
Latency.
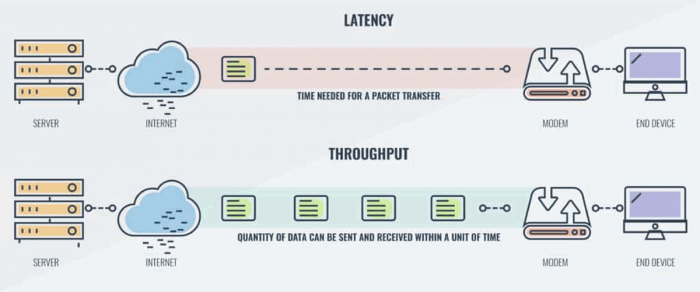
What is low latency? With most HPC fabrics, you can get the round-trip time (data back and forth – pingpong) down to 1.3![]() s (0.0000013s). If you consider a normal data-centre ethernet you will typically see 45
s (0.0000013s). If you consider a normal data-centre ethernet you will typically see 45![]() s – over 30x higher.
s – over 30x higher.
How is this achieved?
Quite simply, it’s through the use of Remote Direct Memory Access or RDMA.
One implementation, RoCE (RDMA over converged ethernet), allows the application to bypass the operating system, directly access the fabric, and insert data straight into memory on a remote server. Bypassing all the usual security, permissions and safety mechanisms: what could possibly go wrong?

The application quite literally inserts data into the memory of a remote application without any real checks and balances.
As a side impact, RDMA drastically reduces the CPU overhead of network communications. Without RDMA, really-fast network interfaces can consume several CPU cores just to process the network packets.
Ultra-low latency is critical to operating a large number of servers as a single computer.
If you enjoyed this HPC Networking post, follow us on Twitter to receive regular updates.
(Brilliant cartoons thanks to Geek & Poke).