High Performance Computing (HPC) networking is very different to the traditional networks that ISP’s, businesses and enterprises build. The ideas and concepts are orthogonal.
The whole system has to be thought of as a single ‘computer’ with an internal fabric joining it together. HPC fabrics are mostly ‘set and forget’: initially requiring substantial setup and configuration, but with few changes over the life of the system.
The critical concept of HPC fabrics is to have massive scalable bandwidth (throughput) whilst keeping the latency ultra-low. In this four-part series we discuss what makes HPC Networking truly unique. This is Part 2: Bandwidth. You can go back and read Part 1: Latency here.
Bandwidth.
In order to solve the bandwidth problem exotic fabric topologies must come to the fore. HPC systems attempt to maintain full, or a high percentage of, bisection bandwidth.
What is bisection bandwidth? Consider an imaginary ‘cut’ in your fabric, which divides it evenly in half. What is the total bandwidth across that cut? For example: 100 servers on the left, 100 servers on the right. Across the cut you want enough bandwidth to handle all the left nodes talking to all the right nodes. Consider each server with 10Gb/s connection, then you would need 100x10Gb/s = 1000Gb/s of bandwidth from the left to the right.
Now consider what happens if you have 20,000 nodes on the left and 20,000 nodes on the right… a 40,000 port switch does not exist, so what do you do?
In order to achieve these levels of bandwidth the HPC community has turned to specially-designed fabrics, which have multiple (thousands?) of connections from one side to the other, and then have the traffic load-balanced across all those connections to avoid hot-spots. Daisy-chaining switches together is not adequate, even if you use trunks/link-aggregation.

Let me introduce you to the king of fabrics – the ‘fat-tree’. This topology is excellent at maintaining full bisection bandwidth and, if implemented well, provides consistent latency and performance.
The basic design allows you to have a large number of server-facing ports – built from small switches (typically 1RU or 2RU), connected together in a fat-tree.
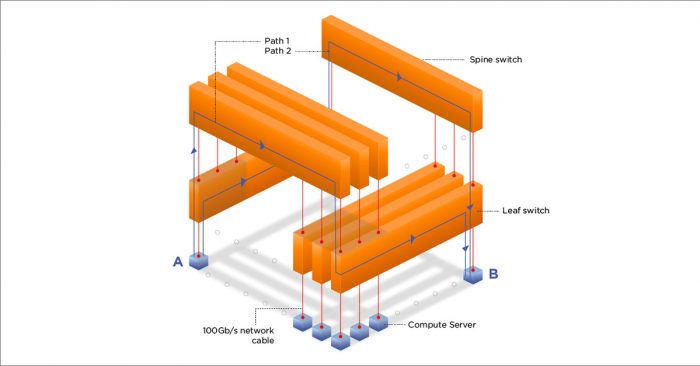
As you can see, there are LOTS of paths from A to B via each spine switch. If you consider this design built from 32 port 100Gb switches, each leaf will have 16 ports down to compute servers and 16 ports up to the spine. You then have 16 spine switches. Each spine switch can connect to 32 leaf switches.
This gives you 32 leaves * 16 compute servers = 512 compute servers.
Utilising 32 leaf +16 spine = 48 switches.
That is 512 x 100Gb/s compute servers attached to a fabric which supports EVERY server doing the full 100Gb/s without contention.
You can increase the number of server ports by either using a ‘super-spine’ (another layer), or having more ports down and less ports up (eg. 24 down and 8 up gives 768 compute servers). Or utilise different cabling and leaf switches to deliver reduced bandwidth to compute servers (eg. 10Gb connected servers using 48x10Gb/s + 4x100Gb/s leaf switches and 100Gb spine switches).
Depending on your workload, you may find that a 3D-torus, dragon-fly or hypercube network topology would be suitable. These have less bisection bandwidth, but still offer very high levels of performance with low latency.
Phew: that’s bandwidth in a nutshell. Stay tuned for Part 3 coming soon: Resilience.
If you’re enjoying our HPC Networking series, follow us on Twitter for regular updates.