High Performance Computing (HPC) networking is very different to the traditional networks that ISP’s, businesses and enterprises build. The ideas and concepts are orthogonal.
The whole system has to be thought of as a single ‘computer’ with an internal fabric joining it all up. They are mostly ‘set and forget’ which require a lot of setup and configuration, with few changes over the life of the system.
The critical concept with HPC fabrics is to have massive amounts of scalable bandwidth (throughput) whilst keeping the latency ultra-low. In this four-part series we discuss what makes HPC Networking truly unique. This is Part 3: Resilience. You can go back and read Part 1: Latency here and Part 2: Bandwidth here.
Resilience.
As can be seen in the fat-tree diagram, there are multiple equal-cost paths from A to B. With a well implemented fabric, you can lose any spine and only suffer a drop in aggregate bandwidth (eg. 1/16 bandwidth in the example). If you lose a leaf, you lose connectivity to the compute servers attached.
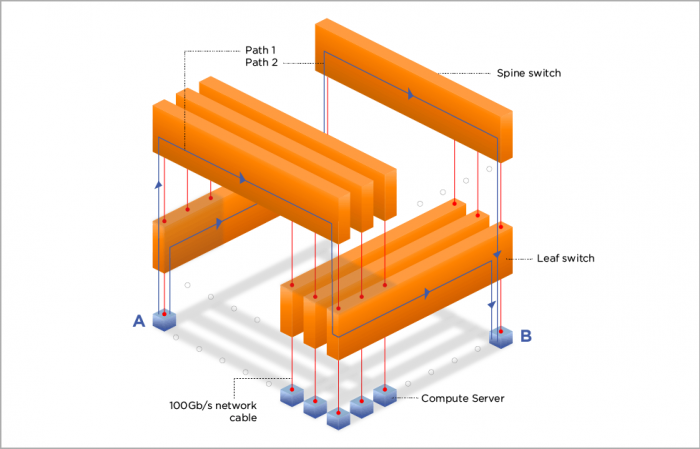
Fat-tree fabric diagram.
The latter can be handled by replicating the fat-tree and going ‘dual-rail’ which means that each compute server is attached to two fat-tree fabrics. While this appears to double the cost, it doesn’t necessarily.
In this case, each individual connection to the servers is 50Gb/s, with an aggregate of 100Gb/s. This doubles the number of servers attached to each fat-tree.
This dual-plane fat-tree provides 100% resilience to switch failure and at most means you lose 50% of your bandwidth. The rest of the fabric still delivers full bandwidth.
Keep an eye out soon for the final installment in our HPC networking series: Protocols.
If you’re enjoying our HPC Networking series, follow us on Twitter for regular updates.