High Performance Computing (HPC) networking is very different to the traditional networks that ISP’s, businesses and enterprises build. The ideas and concepts are orthogonal.
The whole system has to be thought of as a single “computer” with an internal fabric joining it all up. They are mostly “set and forget” which require a lot of setup and configuration, with few changes over the life of the system.
The critical concept with HPC fabrics is to have massive amounts of scalable bandwidth (throughput) whilst keeping the latency ultra-low. In this four-part series we discuss what makes HPC Networking truly unique. This is Part 4: Protocols. You can go back and read Part 1: Latency here. Part 2: Bandwidth here. And Part 3: Resilience here.
Protocols.
Previously we discussed various schemes to provide high bandwidth and low latency. Now that the cabling is done and the servers plugged in, the final step is to use some sort of multi-path routing protocol to balance your transfers across the fabric.
The least-used HPC protocol is ethernet. The ability to build advanced topologies in ethernet has only just become possible with BGP or other protocols stacks such as TRILL, lsp/ospf/mpls/vpls and vxlan. The tricky part is getting the ‘equal-cost multi path’ (ECMP) routing to work. Somehow you have to get your traffic balanced over all the possible links through the fabric. Many of the ethernet-based protocols are single-hope-based (as opposed to path-based) where each switch makes an independent decision.
The most common HPC protocol is Infiniband. This was specifically designed for HPC and has advanced topologies at its heart. The server hardware and switches know about the full fabric and make full-path length decisions.
Another common HPC protocol is OmniPath from Intel which is similar to Infiniband but uses less capable network interface cards and shifts a lot of the network stack to the driver in the OS.
HPE-Cray has an ethernet fabric called SlingShot which uses specially-designed network interface cards and switches with sophisticated congestion control to ensure consistent latency and bandwidth.
Path-based protocols tend to perform better as traffic is sent along the optimal path and load balance is performed across all possible paths. This generally reduces hot-spots in the fabric at the expense of complexity at the servers. It can also mean recovery from a failure can take a short while as the whole fabric needs to re-learn the topology. All hardware needs to participate in the full fabric which can restrict what services are provided.

Single-hope-based protocols like BGP can deal with failures in the fabric faster and allow connectivity to hardware not participating in the whole fabric. Usually the demands on the servers are considerably less, but it is easier to end up with hot-spots – which effectively reduce bandwidth and increase latency.

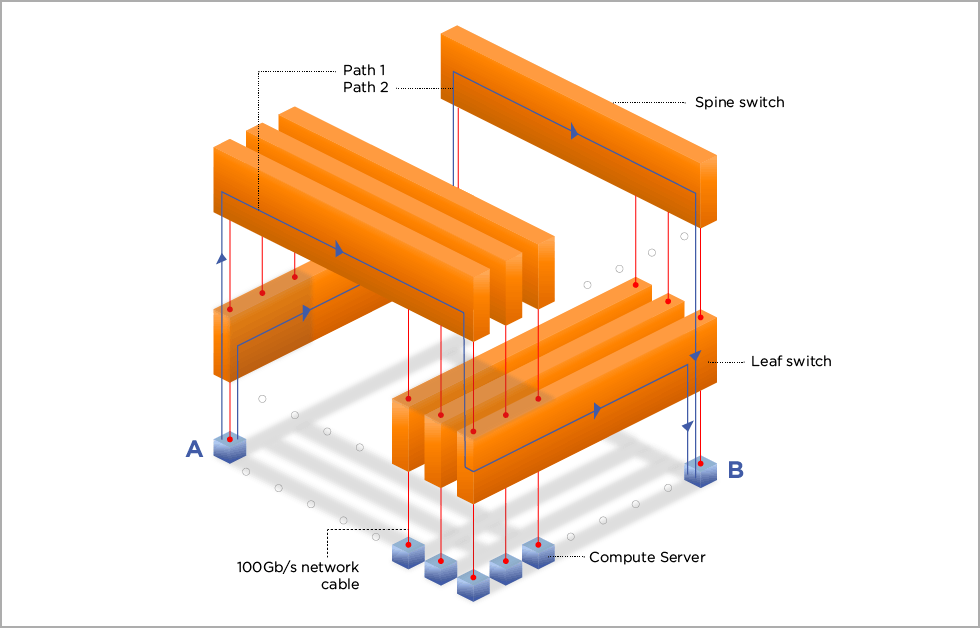
Consider our previous fat-tree network and the two paths. ‘A’ sends traffic to the leaf switch, which then forwards the traffic to one of the spines. Typically, the spine would send the traffic to the correct leaf – connected to ‘B’. BUT if that link is congested it may send the traffic to another leaf, which then forwards it to another spine, and then to the leaf connected to B. This ‘hop-based’ decision can lead to packets bouncing around, getting increased latency, causing excess congestion and packets to arrive out-of-order at the receiver. This process can have a severe impact on performance.
A path-based solution would intuitively recognise the congestion and the sender would choose a path that is least affected. In this method, the traffic should not be re-routed and deliver consistent latency, resulting in packets arriving more ordered.
We hope you enjoyed our four-part series on HPC Networking. Follow us on Twitter for more HPC updates.