If you tuned into Tesla’s AI Day live stream held in late August, you probably had a ‘WTF moment’ when an alien go-go dancer made an appearance, donning a white bodysuit and a shiny black mask. It wasn’t some Tesla stunt, but rather a first look at the Tesla Bot, a humanoid robot that Tesla is currently developing.
Yup, the robot stole the show. But Tesla also unveiled a brand-new computer chip that will power its Dojo project, Tesla’s upcoming massive supercomputer, and most likely the Tesla Bot too.
Dubbed D1, the Technoking of Tesla promises that the chip will conquer artificial intelligence (AI) training for self-driving Tesla battery electric vehicles (BEVs).
Jam-packed with supercomputing power.
During the live stream, Tesla’s Autopilot Hardware Director Ganesh Venkataramanan explained that the D1 chip is a custom application-specific integrated circuit (ASIC), designed and built entirely in-house to train AI models used in Tesla’s data centres. This will allow Dojo to process imaging data four times faster than other computing systems.
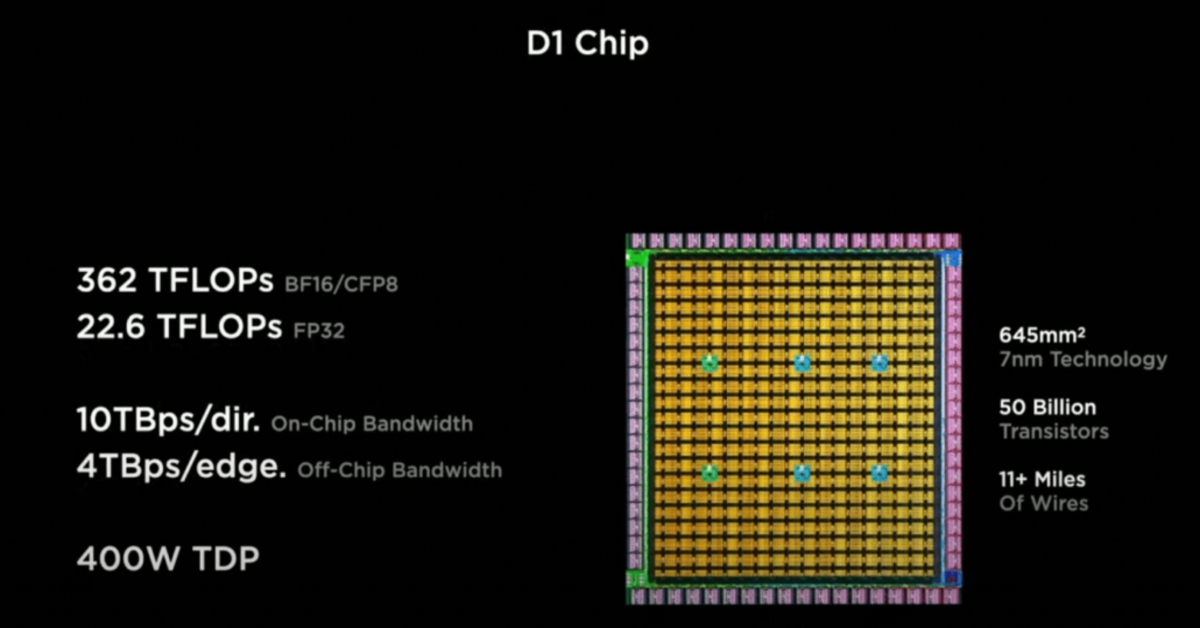
Each chip contains 354 ‘training nodes’ manufactured based on a 7-nanometre semiconductor node, packing over 50 billion transistors over a die size of 645 square millimetres. This means that the chip has an effective transistor density of approximately 77.52 million transistors per square millimetre. In comparison, Apple’s latest M1 Max chip, manufactured on TSMC’s 5 nm process, packs 57 billion transistors over 425.1 square millimetres, giving it a transistor density of 134 million transistors per square millimetre.
D1 has some impressive performance claims. Tesla said an entire chip can output as much as 362 trillion floating-point operations per second (teraFLOPs) at FP16/CFP8 precision, or about 22.6 teraFLOPs of single-precision FP32 tasks. In contrast, the NVIDIA A100 80 GB GPU that powers Tesla’s current and latest supercomputer does 312 teraFLOPS at FP16 and 19.5 teraFLOPS at FP32.
“There is no dark silicon, there is no legacy support. This is a pure machine learning (ML) machine with chips of GPU-level compute but CPU-level flexibility and twice the network chip-level I/O bandwidth,” said Venkataramanan.
D1 training tile.

The integrated training tile, which contains 24 D1 chips. Photo credits: Tesla
For Dojo, Tesla envisioned a large compute plane filled with very robust compute elements, packed with a large pool of memory – all interconnected with very high bandwidth and very low latency fabric.
Perhaps that’s why Tesla is focusing a lot on modularity across the D1 hardware. Each chip is equipped with four TB per second off-chip bandwidth on each of its lateral edges – all four equipped with connectors – allowing it to connect to and scale with other D1 chips without compromising speed.
25 of the D1 chips make up a ‘training tile’, which is around 0.03 cubic metres in size. Each tile operates with a similar modularity to the chip itself, where power and cooling are conducted through the top of the tile, allowing its edges to be outfitted with high-output connectors designed for maximum bandwidth. This gives each chip a total of 36 TB per second of off-tile bandwidth and around nine petaFLOPS of compute.
Enter Dojo.
According to Tesla, here’s what constitutes the Dojo supercomputer ExaPOD, the massive ML machine with uniform bandwidth: ten cabinets, with each cabinet containing two trays, with each tray containing six of the aforementioned training tiles. Essentially, what they do is tile together lots of tiles.
Now let’s do some math here.
Since each D1 chip is capable of 362 teraFLOPS, this means the whole Dojo system is capable of almost 1.1 exaFLOPS of AI compute, with over a million training nodes. (362 teraFLOPS * 25 D1 chips * 6 training tiles * 2 trays * 10 cabinets = 1,086,000 teraFLOPS = 1.086 exaFLOPS)
With the advent of Dojo, Tesla’s BEVs will surely grow a new set of wings – capable of much accurate self-navigation, of course!
But will it also bring an army of 5’8” humanoid robots to life? We’ll have to see how things pan out, particularly the ethical aspect of it.